trojAI detect
Agent-Led Red Teaming That Uncovers AI Risks
Test AI agents and models to reveal unsafe behavior and security risks. Find security weaknesses before they can be exploited.
the problem
Unpredictable Agent Behavior Expands Enterprise Risk
Agents don’t follow a fixed script. Their non-deterministic nature means the same input can produce different outputs, including unsafe, non-compliant, or exploitable behavior. Agent-to-agent interactions coupled with downstream tool calls further multiply the attack surface, and manual testing cannot keep pace with dynamic, multi-agent AI environments.
the solution
Reduce Real-World Risk
with Agent-Led AI Red Teaming
Visibility into the security risks and flaws of AI systems requires thorough testing.
TrojAI Detect delivers continuous agent-led AI red teaming that identifies how AI agents can be manipulated, ensuring AI deployments are secure, robust, and trustworthy.
key features
AI Red Teaming Built for Modern Agentic Systems
Test AI systems adaptive AI agents designed to simulate real-world attacks.
Protect Against Adversarial Attacks
- Prompt Injection — Direct and indirect attacks that attempt to manipulate agent or model behavior
- Jailbreaking — Attempts to bypass model safeguards, policies, or controls to generate restricted, harmful, or unauthorized outputs
- Data Leakage — Exposure of sensitive or confidential data through model inputs, outputs, or connected systems
Prioritize and Mitigate Risk
Prioritize risk based on severity, enabling you to mitigate potential threats, reduce organizational risk, and protect against financial and reputational damage.
Adaptive Learning
Maintain conversational state, memory, and context across multi-step interactions to simulate how real attackers adapt over time.
Adversarial Content
Leverage thousands of out-of-the-box attacks, manipulations, and adversarial testing scenarios. Manually configure tests or accelerate testing using TrojAI’s proprietary fine-tuned adversarial models and custom datasets.
Comprehensive Reporting with Actionable Insights
Map findings to OWASP, MITRE, and NIST frameworks, providing actionable reporting that supports governance, compliance, and risk-based remediation.
how it works
Agent-Led AI Red Teaming
Built for the Speed of AI
Keeping pace with AI innovation requires security testing that can adapt at the same speed. TrojAI Detect uses AI agents to automate and scale testing across evolving attack patterns and behaviors.
Single-Turn Attacks
TrojAI Detect's attack library includes thousands of security tests and manipulations to find defects in AI agents. Customizable and content-specific policies allow you to fine-tune testing and ensure the transparency and security of AI systems.
Multi-Turn Attacks
Uncover vulnerabilities that only emerge across multi-step conversations. By tracking context, state, memory, and continuity, TrojAI Detect realistically simulates attacks to uncover nuanced failures.
Agentic Attacks
Go beyond automated testing with autonomous AI agents that dynamically plan, adapt, and execute complex attack strategies. TrojAI Detect simulates chained exploits across tools, workflows, and conversations.
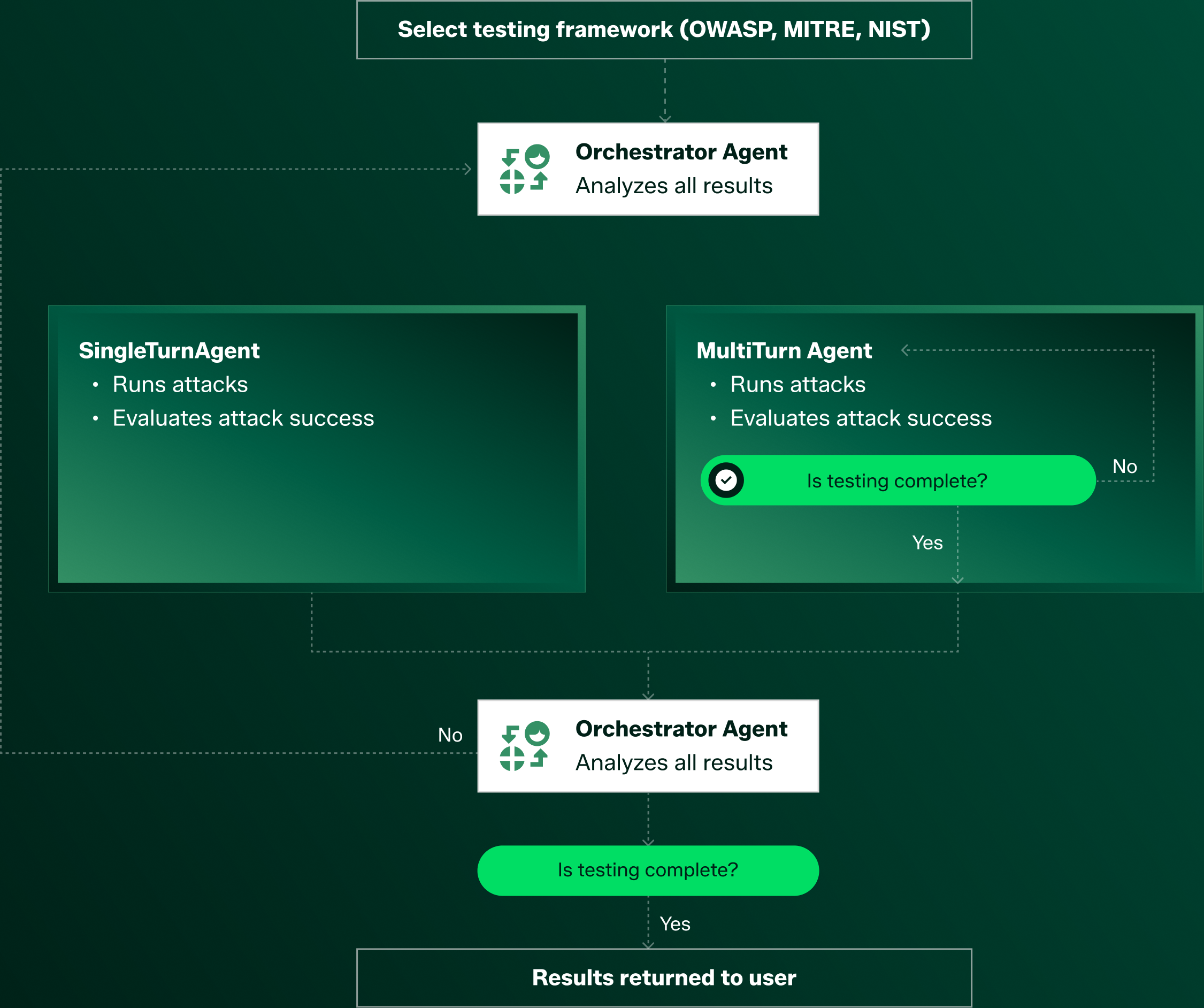
An Orchestrator Agent creates tests based on security frameworks, builds testing strategies, and hands off requirements to SingleTurn and MultiTurn Agents. When testing is complete, it analyzes all results.
A SingleTurn Agent runs and evaluates single-turn attacks then sends results to the Orchestrator Agent.
A MultiTurn Agent runs conversational attacks, evaluates those attacks, and sends results to the Orchestrator Agent.
product in action
Secure AI at Scale
TrojAI Detect allows enterprises to innovate securely at scale
Simulate real-world adversarial attacks
Expose unsafe, unpredictable, and policy-violating AI behavior
Map risks to major security frameworks like OWASP, MITRE, and NIST
who we serve
Purpose-Built for Modern AI Security Teams
CISOs
Continuous visibility into evolving AI risk
Keep pace with accelerating AI risk using automated red teaming that adapts to emerging attack techniques and changing AI behaviors.
AI Security Architects
Adaptive, framework-driven testing across complex AI systems
Design and validate resilient AI systems with dynamic red teaming that evolves alongside modern agentic architectures.
AppSec & CloudSec Teams
AI security testing for cloud-native AI applications
Embed automated AI red teaming into security and deployment pipelines to detect vulnerabilities across AI agents and applications.

TrojAI: Building the Future of AI Red Teaming

“As organizations scale their use of ChatGPT Enterprise across regulated industries, partners like TrojAI play an important role in helping customers apply their own security, safety, and governance controls. This allows teams to innovate with confidence while staying aligned with internal and external policies.”
OpenAI
25%
more accurate than leading native guardrails.
“A well-designed platform and it clearly is built to empower business users while providing the flexibility and insights needed to drive impactful AI use cases.”
Gartner Peer InsightsEnterprise scale, protecting
100+
applications and 60,000 users at a Fortune 100 financial services company.
10,000+
out-of-the-box prompts and hundreds of manipulations.
Scales to filter more than
1 MILLION
tokens per second